2024 - MSc Genética, Biodiversidade e Conservação (PPGGBC-UESB)
2020 - Biologia com Ênfase em Genética (UESB)
Consultoria Ambiental
Consultoria Estatística
Cursos e Mentorias
Desenvolvimento de Pacotes
O que aprender pra aprender R…
O jeito difícil…
O jeito fácil…
Encontre sua motivação individual
Vantagens em aprender R
Independência pra rodar suas análises
Um maior entendimento da sua própria pesquisa
Oportunidades de carreira
Reproducibilidade: caminha pra se tornar industry standard
e principalmente…
Você não ter que sair correndo atrás de alguém faltando 15 dias pra sua qualificação/defesa querendo aprender R pra rodar tuas análises e estatística pra interpretar teus dados.
# A tibble: 6 × 3
Tabela 2. Número de pacientes homens e mulheres e os motivos que…¹ ...2 ...3
<chr> <chr> <chr>
1 <NA> <NA> <NA>
2 Motivos Home… Mulh…
3 Restauração 20 35
4 Implante 5 20
5 Limpeza 15 30
6 Extração 25 15
# ℹ abbreviated name:
# ¹`Tabela 2. Número de pacientes homens e mulheres e os motivos que frequentam o consultório odontológico durante o período de um ano.`
head(dados_folha_2)
# A tibble: 2 × 13
Temperatura Segunda Terça Quarta Quinta Sexta Sábado Domingo ...9 MÉDIA
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <lgl> <lgl>
1 Primeira semana 27 32 31 30 29 30 31 NA NA
2 Segunda semana 25 30 32 27 29 28 32 NA NA
# ℹ 3 more variables: VARIÂNCIA <lgl>, DP <lgl>, CV <lgl>
Importando Dados
Planilhas
Podemos definir além da folha um intervalo de células na mesma notação do Excel.
dados <-read_excel("data/dados_var.xlsx", sheet =1, range ="A3:C9")dados_folha_2 <-read_excel("data/dados_var.xlsx", sheet =2, range ="A1:H3")
Em alguns casos nosso arquivo pode não ter um cabeçalho com o nome das variáveis.
O argumento header = FALSE garante que a primeira linha não seja lida como cabeçalhos neste caso.
A função read_csv() faz a leitura de um arquivo padrão separado por vírgulas, entretanto, alguns programas exportam .csv com ponto e vírgula como separador.
Pra isso temos a função read_csv2(). O processo de importação é idêntico.
Por padrão a nova variável é adicionada ao final do dataset, mas esse comportamento pode ser modificado usando os argumentos .before ou .after e explicitando antes ou depois de qual coluna desejamos nossa nova variável.
Operador pipe
O operador |> (pipe) liga operações em um fluxo contínuo da esquerda para a direita.
O pipe original %>% surgiu com o tidyverse, seu impacto foi tão grande na linguagem que há alguns anos atrás os desenvolvedores do R incluíram um operador nativo na linguagem.
Utilizando o pipe podemos realizar uma sequência de inúmeras operações evitando a criação de objetos intermediários para armazenar os resultados.
No fluxo o objeto à esquerda será o alvo da operação da direita.
Num fluxo com o pipe o operador sempre deve aparecer ao final da linha em caso de quebra:
A função nativa summary() nos fornece um rol de estatísticas descritivas
dados |>summary()
Motivos Homens Mulheres
Length:6 Min. : 1.00 Min. : 4.00
Class :character 1st Qu.: 7.50 1st Qu.:14.25
Mode :character Median :15.00 Median :17.50
Mean :13.50 Mean :19.67
3rd Qu.:18.75 3rd Qu.:27.50
Max. :25.00 Max. :35.00
Esta função embora limitada no rol de estatísticas fornecidas, é muito útil para um diagnóstico rápido dos dados. Ela nos permite avaliar o número de dados perdidos (NA) bem como valores fora do intervalo esperado, nossos outliers.
Descritivas segmentadas
Na grande maioria das vezes precisamos calcular estatísticas descritivas agrupadas por níveis de variáveis categóricas. O pacote rstatix é muito eficiente nessa tarefa.
A função group_by() do dplyr agrupa o nossos dados pelos níveis do fator Species, permitindo que as estatísticas sejam calculadas segmentadas e não como um todo para cada variável.
Variando o argumento type temos acesso a diversas estatísticas. Experimente utilizar type = "full".
Inferência Estatística
Pacotes necessários
Nesta sessão utilizaremos alguns pacotes auxiliares, caso não tenham instalado ainda:
Utilizaremos também dados do pacote ecodados, vocês podem fazer a instalação rodando devtools::install_github("paternogbc/ecodados").
Este pacote é parte do excelente livro Análises Ecológicas no R de Da Silva et al. (2022) e é simplesmente um dos melhores livros dedicados a ciência de dados para Ecologia, disponível gratuitamente na internet. Obrigado aos autores mais uma vez!
Teste \(\large t\) para duas amostras independentes
Um teste t baseado em duas amostras é usado para testar a diferença entre duas médias populacionais \(\mu_1\) e \(\mu_2\) quando \(\sigma_1\) e \(\sigma_2\) são desconhecidos, e portanto usamos os desvios amostrais.
As unidades amostrais são selecionadas aleatoriamente
Distribuição normal (gaussiana) dos resíduos
Homogeneidade da variância
Teste \(\large t\) para duas amostras independentes
Exemplo
Usaremos os dados de comprimento rostro-cloacal (CRC) de machos de anfíbios da espécie Physalaemus nattereri (Anura:Leptodactylidae) amostrados em diferentes estações do ano.
Pergunta: Existe diferença na média co CRC em P. nattereri entre as estações?
Hipótese Nula: As médias de CRC são iguais.
Hipótese Alternativa: As médias de CRC são diferentes entre as estações.
Antes de realizarmos o teste \(t\), precisamos nos certificar de que nossos dados atendem as premissas.
Two Sample t-test
data: CRC by Estacao
t = 4.1524, df = 49, p-value = 0.000131
alternative hypothesis: true difference in means between group Chuvosa and group Seca is not equal to 0
95 percent confidence interval:
0.2242132 0.6447619
sample estimates:
mean in group Chuvosa mean in group Seca
3.695357 3.260870
Ao apresentar os seu resultados inclua:
A estatística \(t\): \(t = 4.1524\)
O p-valor: \(p-value = 0.000131\)
Graus de Liberdade: \(df = 49\)
Diferenca entre as médias: \(0.434\)
Teste \(\large t\) para duas amostras independentes
No teste \(t\) pareado temos duas observações da mesma unidade amostral subetida ao tratamento/efeito de interesse. O nosso objetivo é determinar se a diferença entre observações é zero.
As unidades amostrais são selecionadas aleatoriamente
As observações não são independentes
Distribuição normal (gaussiana) dos valores da diferença para cada par
Teste \(t\) pareado
Exemplo
Novamente vamos utilizar dados do pacote ecodados seguindo o exemplo disponível em Da Silva et al. (2022). Vamos utilizar dados de riqueza de espécies de artrópodes em uma área antes e depois de um processo de queimada.
Pergunta: A riqueza de espécies de artrópodes é afetada pelas queimadas?
Hipótese Nula: A riqueza de espécies é igual antes e depois.
A função é a mesma t.test(), porém precisamos informar que agora estamos avaliando dados pareados, isso é feito pelo argumento paired = TRUE. Uma outra diferença é que para o teste pareado, não podemos utilizar a notação de fórmula, precisamos declarar explicitamente nossos dois vetores de observações. O restante da análise segue a anterior.
Paired t-test
data: rich_antes and rich_depois
t = 7.5788, df = 26, p-value = 4.803e-08
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
32.47117 56.63994
sample estimates:
mean difference
44.55556
Teste \(t\) pareado
Exemplo
Como no exemplo anterior podemos apresentar nossos resultados de maneira gráfica. A função ggpaired() do pacote ggpubr nos fornece uma maneira bastante didática de apresentar nossos resultados.
ggpubr::ggpaired(art_rich, x ="Estado", y ="Riqueza",color ="Estado", line.color ="gray", line.size =0.8,palette =c("#606c38", "#dda15e"), width =0.5,point.size =4, xlab ="Estado das localidades",ylab ="Riqueza de Espécies") +expand_limits(y =c(0, 150)) +theme_classic(base_size =14, base_family ="Ubuntu") +theme(legend.direction ="horizontal",legend.position ="top")
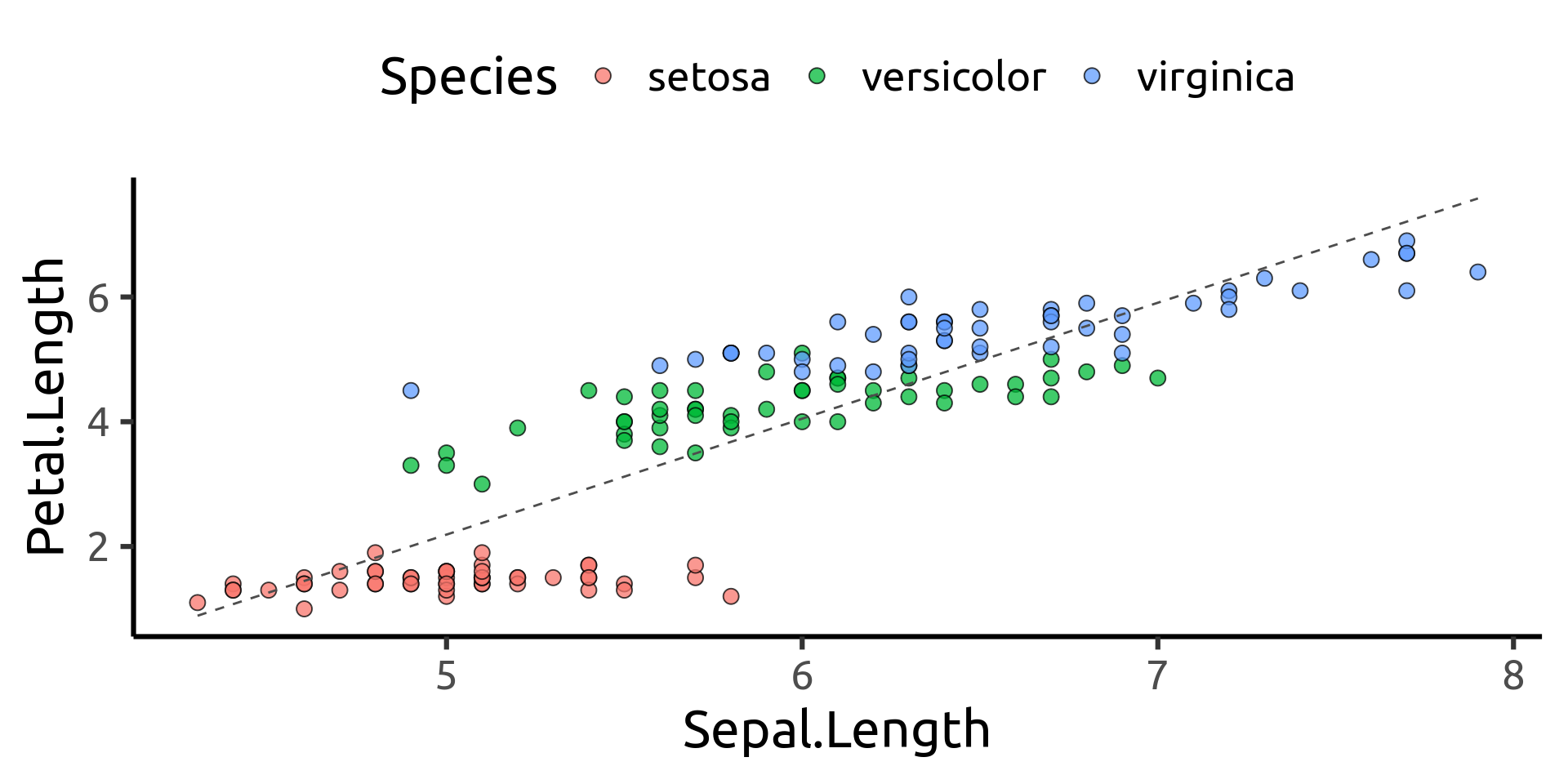
Uma correlação é uma relação entre duas variáveis. Os dados podem ser representados por pares ordenados (x, y), sendo x a variável independente (ou explanatória) e y a variável dependente (ou resposta). (Larson and Farber, 2023)
library(ggtext)ggplot(dados_pib_co2,aes(x = PIB, y = CO2)) +geom_point(shape =21, size =4, fill ="grey70", color ="black")+theme_bw(base_size =14, base_family ="Ubuntu") +scale_x_continuous(breaks =1:6) +scale_y_continuous(breaks =seq(0,1200,by =200))+labs(title ="Relação entre PIB e a quantidade de CO2 emitida, para amostra com 10 países.",x ="PIB <br> (em trilhões de dólares)",y ="CO<sub>2</sub> <br> (em milhões de toneladas métricas)") +theme(axis.title =element_markdown())
Correlação de Pearson
Mais uma vez usaremos dados do ecodados de (Da Silva et al., 2022). Neste exemplo, avaliaremos a correlação entre a altura do tronco e o tamanho da raiz medidos em 35 indivíduos de uma espécie vegetal arbustiva.
A regressão linear simples é usada para analisar a relação entre uma variável preditora (plotada no eixo-X) e uma variável resposta (plotada no eixo-Y). As duas variáveis devem ser contínuas. Diferente das correlações, a regressão assume uma relação de causa e efeito entre as variáveis. O valor da variável preditora (X) causa, direta ou indiretamente, o valor da variável resposta (Y). Assim, Y é uma função linear de X (Da Silva et al., 2022).
\[\Large y = \beta_0+\beta_1 X_i + \varepsilon_i\] Este é o modelo matemático que define uma Regressão Linear Simples, onde:
\(\large y\) é o nosso vetor de observações da nossa variável resposta
\(\large \beta_0\) é o intercepto (intercept) que representa o valor da função quando \(X = 0\)
\(\large \beta_1\) é a inclinação (slope) que mede a mudança na variável \(y\) para cada mudança de unidade da variável \(X\)
\(\large \varepsilon_i\) é no nosso vetor de erros aleatórios ou resíduos, é toda variabilidade em \(\large y\) que não pode ser explicada por \(X\)
Regressão Linear Simples
A regressão linear também possui premissas:
As amostras devem ser independentes
As unidades amostrais são selecionadas aleatoriamente
Distribuição normal (gaussiana) dos resíduos
Homogeneidade da variância dos resíduos
Regressão Linear Simples
Exemplo
Avaliaremos a relação entre o gradiente de temperatura média anual (°C) e o tamanho médio do comprimento rostro-cloacal (CRC em mm) de populações de Dendropsophus minutus (Anura:Hylidae) amostradas em 109 localidades no Brasil.
Pergunta: A temperatura afeta o tamanho do CRC de populações de Dendropsophus minutus?
mod_rls <-lm(CRC ~ Temperatura, data = den_min)
Utilizando a função plot() podemos fazer a inspeção visual dos resíduos e checar a normalidade e a homogeneidade da variância.
Regressão Linear Simples
par(mfrow =c(2, 2), oma =c(0, 0, 2, 0))plot(mod_rls)
Regressão Linear Simples
Confirmado que nossos dados atendem as premissas de normalidade e heterocedasticidade dos resíduos, podemos agora ver os resultados da nossa regressão usando as funções anova() e summary(). Falaremos de ANOVA (Análise de Variância) na próxima sessão, mas a função anova() quando fornecida um único modelo nos retorna a famosa Tabela da Anova, que nos mostra se os termos do nosso modelo foram significativos.
anova(mod_rls)
Analysis of Variance Table
Response: CRC
Df Sum Sq Mean Sq F value Pr(>F)
Temperatura 1 80.931 80.931 38.92 9.011e-09 ***
Residuals 107 222.500 2.079
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Regressão Linear Simples
A nossa velha amiga summary() nos fornece também a significância dos termos do modelo, e ainda os valores dos coeficientes, e do coeficiente de determinação (\(R^2\)), que indica o quanto da variação em \(y\) é explicada pela nossa variável \(X\).
summary(mod_rls)
Call:
lm(formula = CRC ~ Temperatura, data = den_min)
Residuals:
Min 1Q Median 3Q Max
-3.4535 -0.7784 0.0888 0.9168 3.1868
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 16.23467 0.91368 17.768 < 2e-16 ***
Temperatura 0.26905 0.04313 6.239 9.01e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.442 on 107 degrees of freedom
Multiple R-squared: 0.2667, Adjusted R-squared: 0.2599
F-statistic: 38.92 on 1 and 107 DF, p-value: 9.011e-09
Regressão Linear Simples
Podemos apresentar nossos resultados por meio de um gráfico de dispersão como vimos anteriormente.
Aqui vale comentar sobre as diferentes hipóteses que são testadas em cada função.
A função summary() realiza um teste \(t\) para cada um dos betas do modelo, no nosso caso de uma regressão linear simples o intercepto e o slope. A hipótese nula neste caso é:
Ou seja, o teste avalia se a variável explicativa \(X\) tem efeito significativo sobre \(y\) controlando pelas outras variáveis do modelo.
Regressão Linear Simples
Interpretando os resultados
Já a função anova() está fazendo uma análise de variância (ANOVA) que testa a seguinte hipótese nula global de que todos os coeficientes, exceto o intercepto, são iguais a zero:
\[H_0: \beta_1 = \beta_2 = \cdots \beta_n = 0\]
Mas como falamos de uma regressão linear simples, testamos somente o nosso \(\beta_1\).
Ou seja, o teste \(F\) da ANOVA avalia se o modelo completo com as variáveis preditoras explica significativamente mais variância do que um modelo nulo (só com o intercepto).
Se o valor-p do teste \(F\) for pequeno, rejeitamos \(H_0\) e concluímos que pelo menos uma variável tem efeito significativo sobre a resposta.
Análise de Variância (ANOVA)
Análise de variância com um fator é uma técnica de teste de hipótese usada para comparar as médias de três ou mais populações. A análise de variância geralmente é abreviada como ANOVA.
Como mencionado anteriormente, a ANOVA é um teste de razão de variâncias. O que a estatistica do teste avalia de maneira resumida:
\[Estatística \ do \ Teste = \frac{Variância \ dentro \ dos \ grupos}{Variância \ entre \ grupos}\]
A Estatística \(F\) é o quociente destas duas variâncias, e nossa hipótese nula na ANOVA testa se a média dos grupos é igual:
\[H_0: \mu_1 = \mu_2 = \cdots \mu_n\]
Premissas da ANOVA:
As amostras devem ser independentes
As unidades amostrais são selecionadas aleatoriamente
Distribuição normal (gaussiana) dos resíduos
Homogeneidade da variância
Análise de Variância (ANOVA)
Tabela da ANOVA
Fontes de Variação (FV)
Graus de Liberdade (GL)
Soma de Quadrados (SQ)
Quadrado Médio (QM)
F
Tratamento (entre)
\(p-1\)
\(SQ_{Trat}\)
\(\frac{SQ_{Trat}}{p-1}\)
\(\frac{QM_{Trat}}{QM_{Res}}\)
Erro Experimental (dentro)
\(n-p\)
\(SQ_{Res}\)
\(\frac{SQ_{Res}}{n-p}\)
Total
\(n-1\)
\(SQ_{Total}\)
Esta é a famosa tabela da ANOVA, a mesma tabela que é retornada pelas funções que utilizaremos aqui no R. As somas de quadrado podem ser obtidas como:
# A tibble: 6 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen NA NA NA NA
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
# ℹ 2 more variables: sex <fct>, year <int>
Anova de um Fator
Diferente da última sessão, utilizaremos a função aov() para realizarmos a ANOVA.
anova_bico <-aov(bill_length_mm ~ species, data = pinguins)
Testando Premissas
Assim como fizemos com nosso modelo de regressão linear podemos avaliar nossos resíduos visualmente.
par(mfrow =c(2, 2), oma =c(0, 0, 2, 0))plot(anova_bico)
Anova de um Fator
Nossos resíduos parecem seguir normalidade e homocedasticidade. Mas podemos confirmar realizando os testes de Shapiro-Wilk (normalidade) e Bartlett (homocedasticidade).
Lembre-se que sempre testamos os resíduos!
shapiro.test(residuals(anova_bico))
Shapiro-Wilk normality test
data: residuals(anova_bico)
W = 0.98903, p-value = 0.01131
bartlett.test(bill_length_mm ~ species, data = pinguins)
Bartlett test of homogeneity of variances
data: bill_length_mm by species
Bartlett's K-squared = 5.6179, df = 2, p-value = 0.06027
Lembrando que a hipótese nula em ambos os testes é de que os dados seguem normalidade/homocedasticidade. Confirmamos assim o nosso diagnístico visual.
Anova de um Fator
Tabela Anova
summary(anova_bico)
Df Sum Sq Mean Sq F value Pr(>F)
species 2 7194 3597 410.6 <2e-16 ***
Residuals 339 2970 9
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
2 observations deleted due to missingness
E aqui obtemos a nossa tabela da ANOVA. E com base no p-valor obtido podemos confirmar que existe efeito de Espécie sobre o Tamanho do Bico dos Pinguins. Em relação a nossa hipótese nula, isso significa dizer que pelo menos um dos grupos avaliados possui média diferente dos demais.
Anova de um Fator - Comparação de Médias
Uma vez sabendo que existe diferença significativa, agora precisamos realizar um pós-teste de comparação de médias entre os grupos. Para isso vamos utilizar o pacote agricolae. Este pacote é excelente por possuir diversos pos-testes para anova, entre eles Tukey, SNK, e Duncan.
Tukey HSD
O Teste Tukey HSD (honestly significant difference) é amplamente reconhecido por controlar de forma rigorosa a taxa de erro familiar, permitindo comparações par a par entre todas as médias com um critério bastante robusto.
Study: anova_bico ~ "species"
HSD Test for bill_length_mm
Mean Square Error: 8.760732
species, means
bill_length_mm std r se Min Max Q25 Q50 Q75
Adelie 38.79139 2.663405 151 0.2408694 32.1 46.0 36.75 38.80 40.750
Chinstrap 48.83382 3.339256 68 0.3589349 40.9 58.0 46.35 49.55 51.075
Gentoo 47.50488 3.081857 123 0.2668810 40.9 59.6 45.30 47.30 49.550
Alpha: 0.05 ; DF Error: 339
Critical Value of Studentized Range: 3.329136
Groups according to probability of means differences and alpha level( 0.05 )
Treatments with the same letter are not significantly different.
bill_length_mm groups
Chinstrap 48.83382 a
Gentoo 47.50488 b
Adelie 38.79139 c
Anova de um Fator - Comparação de Médias
SNK
O Teste Student-Newman-Keuls (SNK) realiza comparações par a par de maneira sequencial, equilibrando a sensibilidade para detectar diferenças com um critério menos conservador que o Tukey HSD, mas mais rigoroso que o teste de Duncan.
agricolae::SNK.test(anova_bico, "species", group =TRUE, console =TRUE)
Study: anova_bico ~ "species"
Student Newman Keuls Test
for bill_length_mm
Mean Square Error: 8.760732
species, means
bill_length_mm std r se Min Max Q25 Q50 Q75
Adelie 38.79139 2.663405 151 0.2408694 32.1 46.0 36.75 38.80 40.750
Chinstrap 48.83382 3.339256 68 0.3589349 40.9 58.0 46.35 49.55 51.075
Gentoo 47.50488 3.081857 123 0.2668810 40.9 59.6 45.30 47.30 49.550
Groups according to probability of means differences and alpha level( 0.05 )
Means with the same letter are not significantly different.
bill_length_mm groups
Chinstrap 48.83382 a
Gentoo 47.50488 b
Adelie 38.79139 c
Anova de um Fator - Comparação de Médias
Duncan
O Teste de Duncan adota uma abordagem mais liberal, facilitando a identificação de intervalos de similaridade entre as médias, mas com uma margem maior de risco de erro do Tipo I.
agricolae::duncan.test(anova_bico, "species", group =TRUE, console =TRUE)
Study: anova_bico ~ "species"
Duncan's new multiple range test
for bill_length_mm
Mean Square Error: 8.760732
species, means
bill_length_mm std r se Min Max Q25 Q50 Q75
Adelie 38.79139 2.663405 151 0.2408694 32.1 46.0 36.75 38.80 40.750
Chinstrap 48.83382 3.339256 68 0.3589349 40.9 58.0 46.35 49.55 51.075
Gentoo 47.50488 3.081857 123 0.2668810 40.9 59.6 45.30 47.30 49.550
Groups according to probability of means differences and alpha level( 0.05 )
Means with the same letter are not significantly different.
bill_length_mm groups
Chinstrap 48.83382 a
Gentoo 47.50488 b
Adelie 38.79139 c
Anova de um Fator - Comparação de Médias
Dunnet
O Teste Dunnett é particularmente útil quando o objetivo principal é comparar cada tratamento com um grupo de controle, focando essa análise e ajustando as comparações para esse propósito.
Para realizar esse teste usaremos o pacote multcomp.
Two Sample t-test
data: CRC by Estacao
t = 4.1524, df = 49, p-value = 0.000131
alternative hypothesis: true difference in means between group Chuvosa and group Seca is not equal to 0
95 percent confidence interval:
0.2242132 0.6447619
sample estimates:
mean in group Chuvosa mean in group Seca
3.695357 3.260870
aov(CRC ~ Estacao, data = crc_phy_nat) |>summary()
Df Sum Sq Mean Sq F value Pr(>F)
Estacao 1 2.384 2.3838 17.24 0.000131 ***
Residuals 49 6.774 0.1383
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
That’s all folks!
pbarrosbio@gmail.com
https://paulobarros.com.br
Obrigado pela paciência!
Referências
DA SILVA, F. R. et al.Análises ecológicas no r. [s.l.] Clube de Autores, 2022.
LARSON, R.; FARBER, B. Estatı́stica aplicada: Retratando o mundo. [s.l.] Bookman Editora, 2023.